![[Swift] WWDC16 Understanding Swift Performance(2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdiJiB1%2FbtsplO92Y3R%2FUm71m6nuOmCo81q1wzgd7k%2Fimg.jpg)
저번 글 포스트에 이어서 계속해서 WWDC16 Understanding Swift Performance를 정리해 보겠습니다.
프로토콜 타입의 변수들이 어떻게 저장되며 복사되고, 프로토콜의 method dispatch는 어떻게 작동하는지 알아봅시다.
Protocol Types
아래와 같은 코드를 작성했다고 생각해 봅시다.

위 코드는 Drawable 프로토콜이 정의되어 있고, Point와 Line은 각각 Drawable 프로토콜을 채택하고 있습니다. 그리고 Drawable 타입을 담고 있는 배열도 정의되어 있습니다. 해당 코드는 다형성을 제공합니다.(Polymorphism) 그러나 V-table dispatch를 하는 공통된 상속 관계를 가지고 있지 않습니다.(Point와 Line은 구조체입니다!) 그러면 Swift는 어떠한 방식으로 어떻게 알맞은 타입의 draw 메소드를 호출할 수 있을까요?(method dispatch)
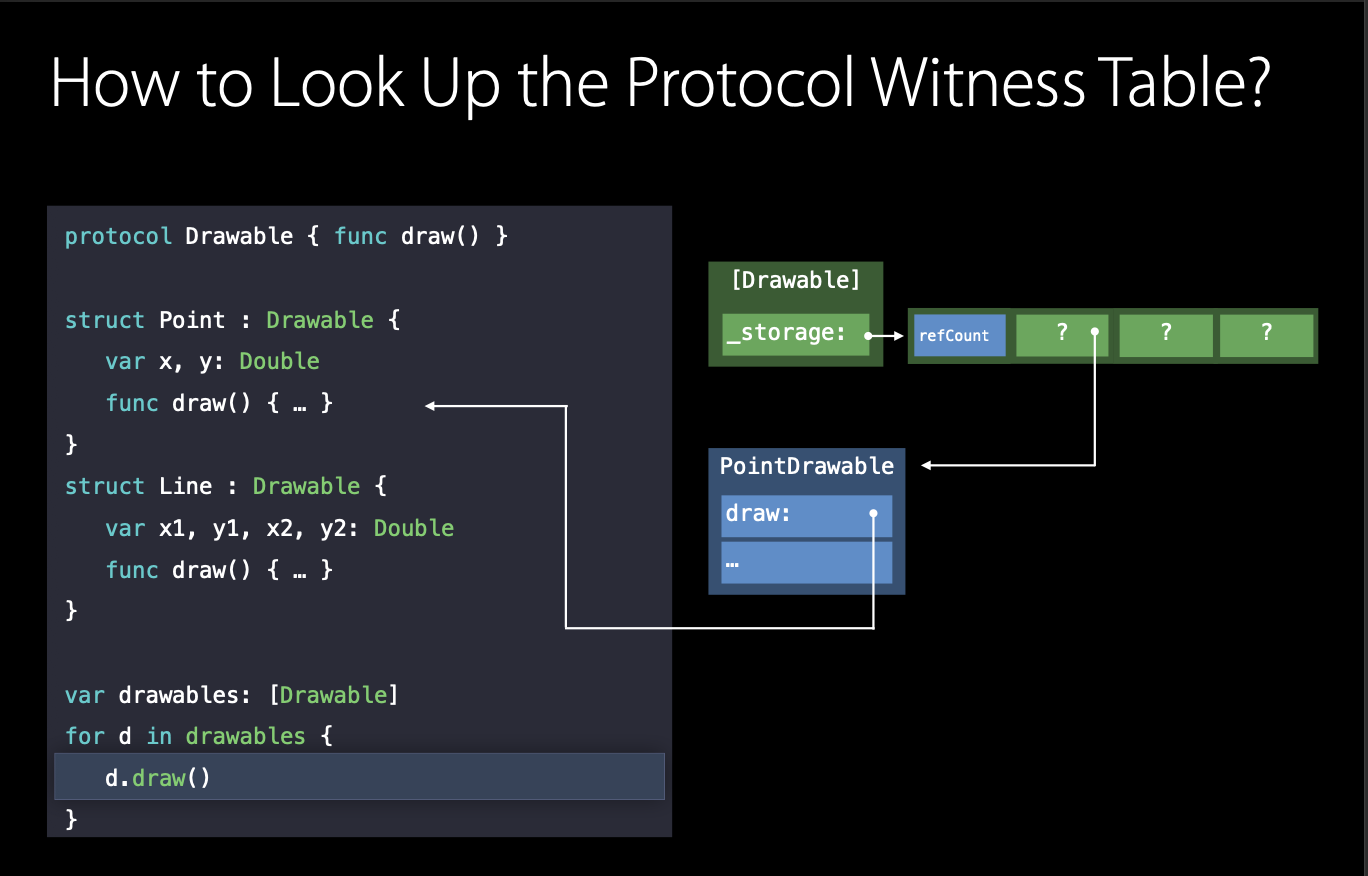
Swift는 위와 같은 경우에 테이블 베이스의 Protocol Witness Table을 활용합니다.
각각의 타입 별로 프로토콜을 구현한 테이블이 존재합니다. 즉 위에서보면 PointDrawable이라고 되어있는 파랑색 테이블이 PWT가 됩니다. 그리고 해당 테이블의 엔트리는 해당 타입의 구현과 link가 되어있습니다. (PointDrawable 파랑색 박스가 draw 메소드와 연결되어있죠!) 이렇게 우리는 해당 타입의 메소드를 찾을 수 있습니다.
이제는 drawable 배열을 조금 더 자세하게 보면서 어떠한 방식으로 배열에 있는 요소들에 접근(or 저장)을 하는지 알아보겠습니다.

Line과 Point 타입은 각각 4개의 프로퍼티, 2개의 프로퍼티를 가지고 있습니다. 두 개의 타입은 서로 다른 사이즈를 가지고 있습니다. 그러나, 배열은 자신의 요소들을 동일한 사이즈로 저장합니다. Swift는 이것을 Existential Container라 불리는 스페셜한 저장 레이아웃(Storage layout)을 활용합니다.
Existential Container
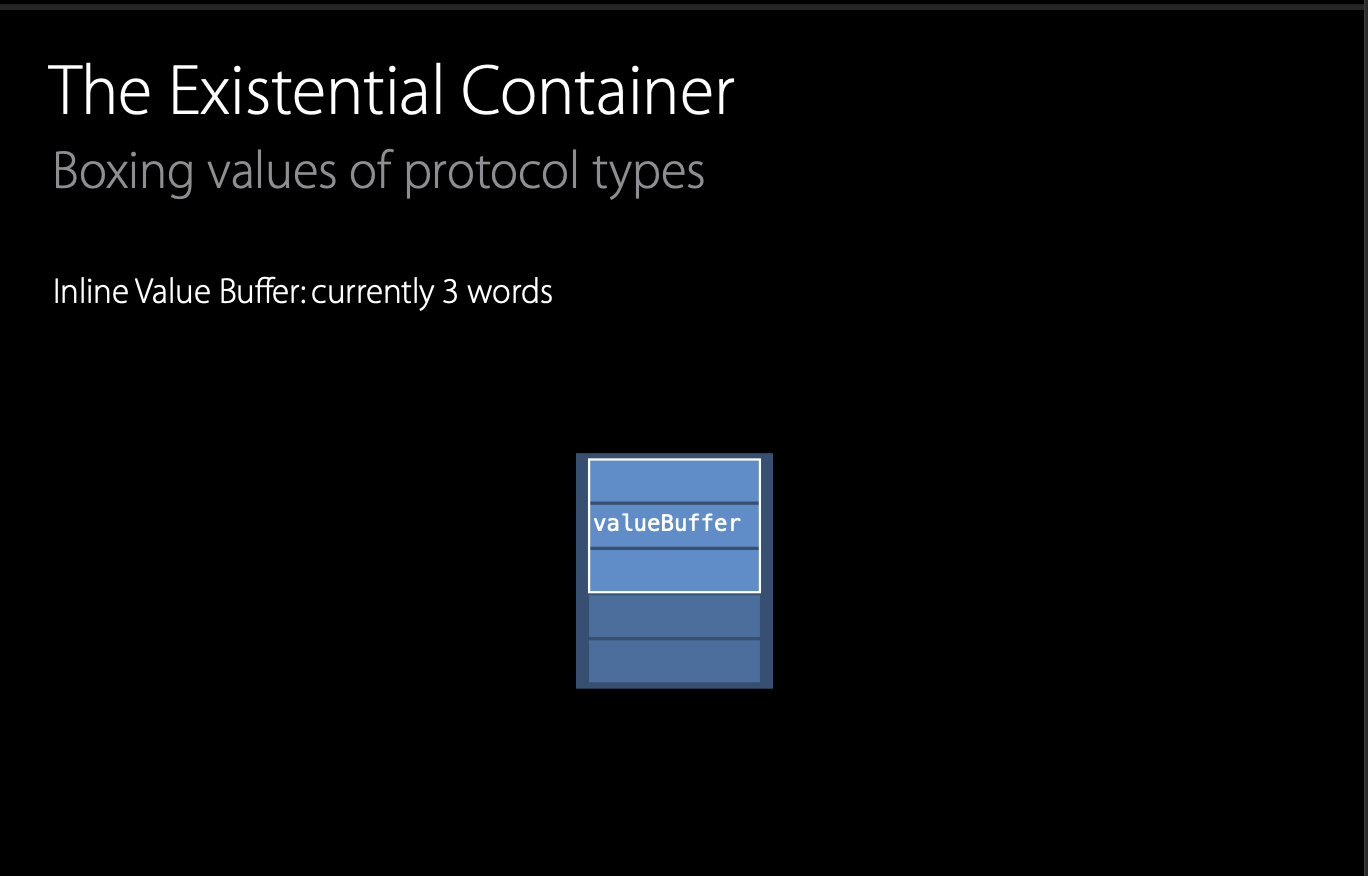
처음 세 개의 단어들은 컨테이너 속 valueBuffer라고 불리는 곳에 예약됩니다.
(cf. 여기서 말하는 단어는 앞서 (1)편에서 말씀드린 것과 같이 프로퍼티의 갯수를 말하는 것이 아닌, 운영체제 마다 다른 byte들의 단위라고 보시면 됩니다! Swift에서는 통상적으로 8바이트를 말한다고 합니다!)

Point와 같이 2개의 프로퍼티를 가지고 있는 타입은 valueBuffer에 맞게 들어가게 됩니다.

그러나, Line과 같이 4개의 단어를 가지고 있는 타입은 valueBuffer 이상의 공간을 필요로 합니다. 이럴 경우, Swift는 heap 메모리를 할당하여 값들을 거기에 저장하고, container 안에 해당 값을 포인팅 하는 포인터를 저장합니다.
(위의 그림에서 초록색 박스가 heap 메모리에 할당된 것이겠죠!)
이렇게 Point와 Line 타입은 서로 다르게 저장이 됩니다. 그렇다면 이러한 차이점을 어떠한 방식으로 Swift는 관리를 할까요?
답은 바로 테이블 기반의 메커니즘인 Value Witness Table입니다.
Existential Container - Value Witness Table

VWT는 4가지의 엔트리를 가지고 있습니다. Value Witness Table은 값의 라이프 타임을 관리하고, 하나의 타입에 하나씩 존재합니다. 그리고 프로토콜 타입의 로컬 변수의 라이프 타임이 시작되면, Swift는 VWT 속 allocate 함수를 호출합니다.

즉, Allocate 함수가 실행되면 Line은 4 words를 넘기에 Heap에 메모리를 할당하고, 해당 값을 포인팅 하는 포인터를 valueBuffer에 저장합니다. (아직 실제 값을 할당하지는 않습니다, (1)에서 알아본 것과 같이 공간을 일단 할당하는 과정인 거 같네요!)

그리고, Copy 함수를 통해서 Swift는 로컬 변수를 초기화하는 assignment의 소스에서 Existential Container로 값들을 복사해옵니다. Line의 경우, Heap에 있는 값들을 Existential Container의 valueBuffer로 복사합니다. 즉, allocate에서 할당한 메모리에 실제 값들을 할당하는 것입니다.(Allocate 함수에서는 Heap 메모리에 공간을 할당했고, Copy 함수에서는 실제 값을 할당해주네요!)
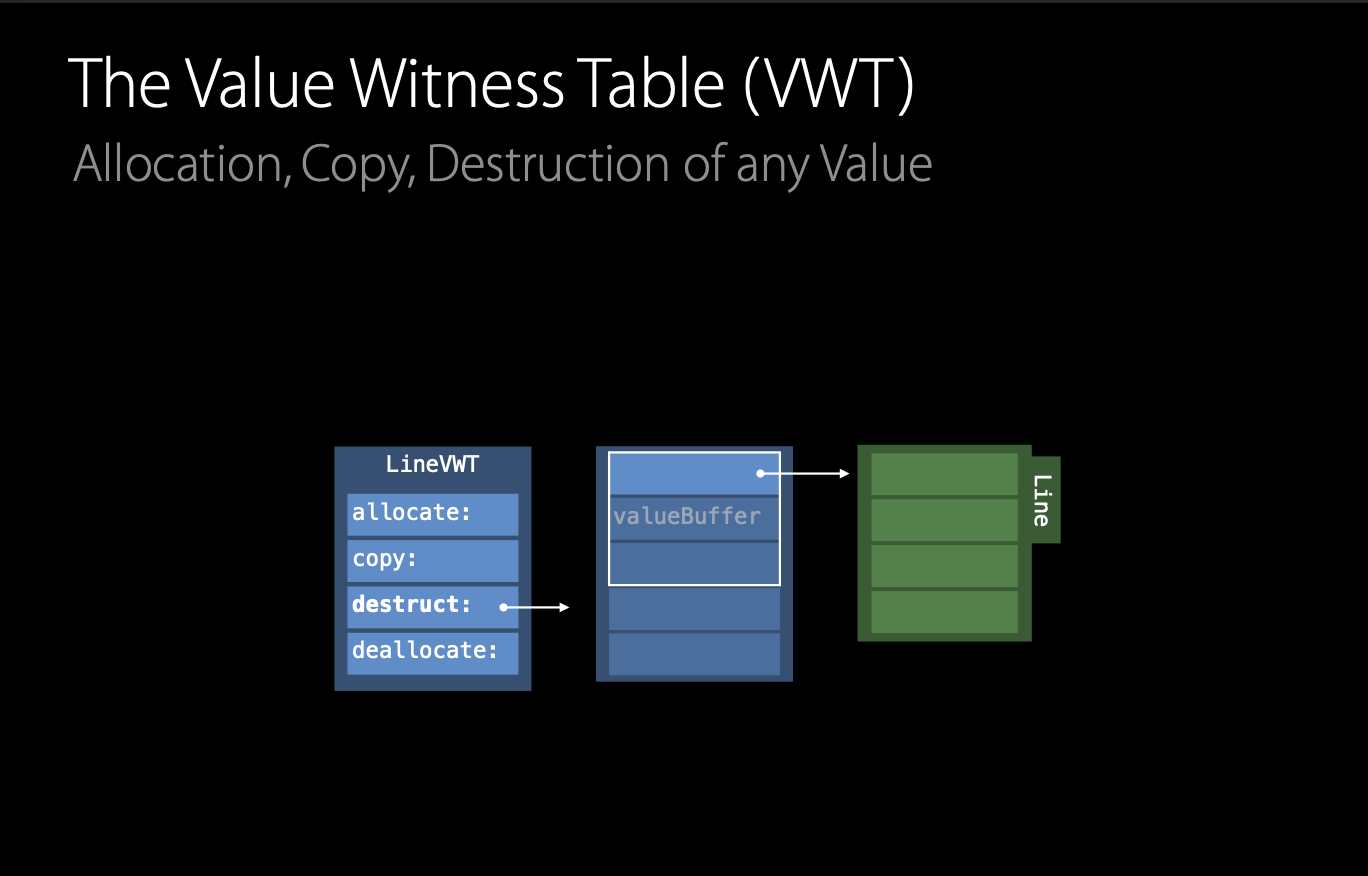
만약 로컬 변수의 라이프 타임이 다 끝났을 경우, Swift는 VWT의 destruct 엔트리를 호출합니다. 호출이 되면, 해당 메소드에 의해 값의 reference count가 감소됩니다.

그리고, 해당 타입이 더 이상 필요가 없을 때, Swfit는 deallocate 함수를 호출시킵니다. 그리고 Heap 메모리 할당을 해제합니다.
자 이렇게 우리는 Line과 Point 타입을 구분하여 Value Witness Table이 어떻게 valueBuffer를 채우는 지는 알아보았습니다. 그러나 Existential Container는 valueBuffer 말고도, 다른 정보를 더 담고 있습니다. valueBuffer말고 나머지에 대해서 더 알아보겠습니다.

Existential Container는 위와 같이 Value Witness Table에대한 참조를 가지고 있습니다.

그리고, 위와 같이 Existential Container는 앞서 배운 Protocol Witness Table에 대한 참조 또한 가지고 있습니다.
(PWT는 각 타입마다 존재하며, 메소드의 실현부와 연결된 link를 가지고 있는 놈이죠!)
앞서 배운 내용들을 한번 정리해보겠습니다.
[Drawable] 배열의 경우, 배열의 요소들이 같은 사이즈여야합니다. 그러나, 프로토콜을 채택하고 있는 타입들의 사이즈는 일정하지 않기에, Swift는 Existential Container라는 것을 활용합니다.
Existential Container는 크게 3가지로 나눌 수 있습니다.
▪︎ Value Buffer
▪︎ Value Witness Table 포인터
▪︎ Protocol Witness Table 포인터
Value Buffer에 타입의 프로퍼티를 저장해야되는데, 이때 VWT가 활용되는 총 4자기의 엔트리를 가지고 있습니다.
▪︎ Allocate - valueBuffer에 들어갈 수 있는 사이즈인지 판단 후, 메모리 공간 마련하기
▪︎ Copy - 실제 값들을 메모리에 올리기
▪︎ Destruct - 라이프 타임이 끝나면, Reference count를 감소시키기
▪︎ Deallocate - 정말 필요가 없다면, 메모리에서 할당해제 해버리기
앞서 VWT는 프로토콜의 저장 프로퍼티(ex. x, y..)를 관리하고, PWT는 프로토콜의 메소드(ex. draw메소드)를 관리하는 것이라고 배웠었죠?
Existential Container는 VWT의 포인터를 가지고 있기에 VWT를 활용하여 ValueBuffer안에 프로퍼티 값을 저장합니다.
그리고 PWT에 대한 포인터 또한 가지고 있기에, Container를 통해서 PWT에 접근하고, PWT를 통해서 해당 타입의 메소드 구현부에 접근할 수 있습니다.
(cf. VWT는 프로토콜의 저장 프로퍼티(ex. x, y..)를 관리하고, PWT는 프로토콜의 메소드(ex. draw메소드)를 관리하는 것이었죠!)
그렇다면 실제 코드에서 Existential Container가 어떻게 작동하는지 알아봅시다.
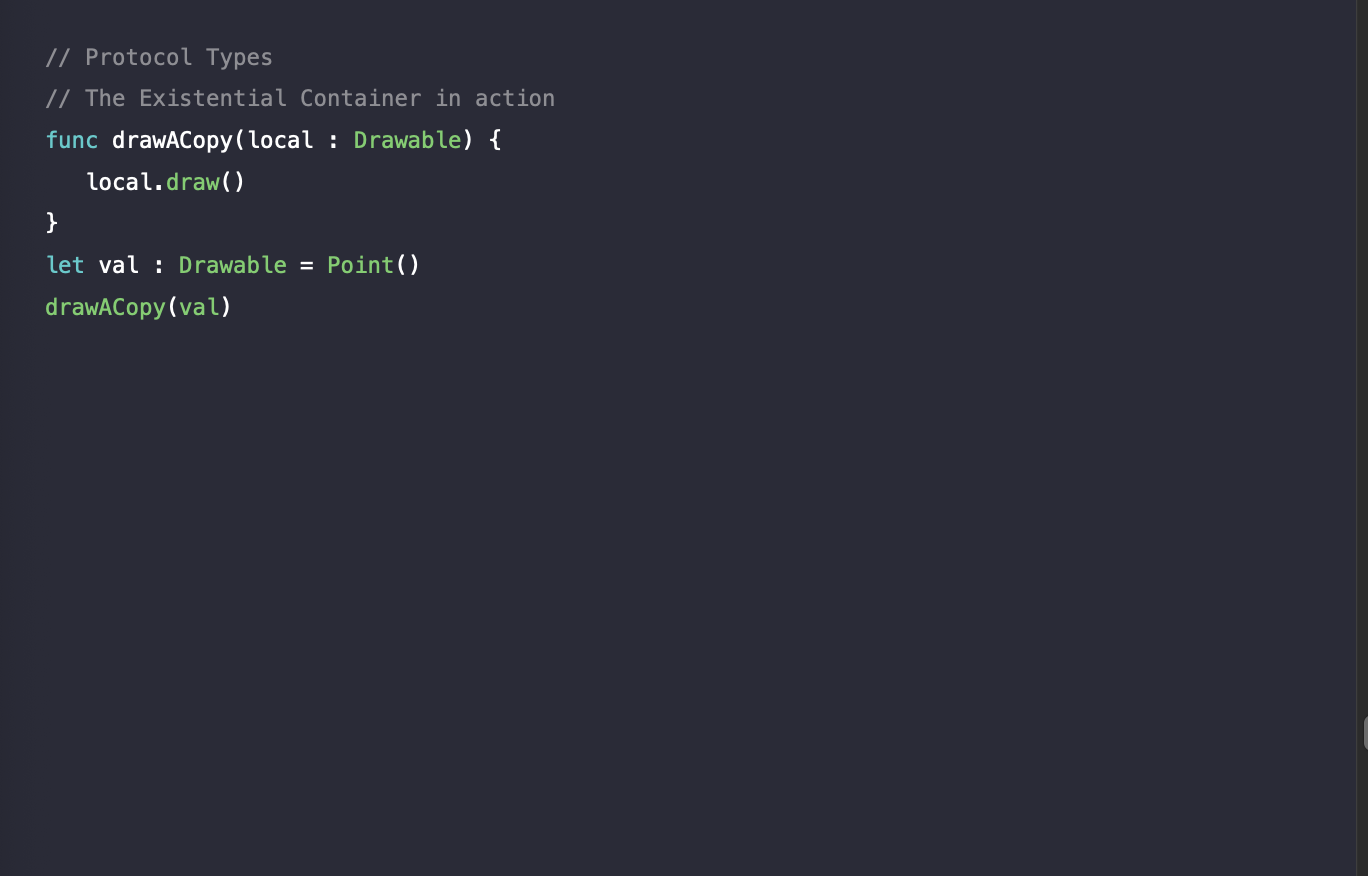
위와 같은 코드가 존재합니다. 이럴 경우 자동적으로 아래의 ExistContDrawable 타입이 정의가 됩니다.

ExistContDrawable 타입은 세 단어를 저장할 수 있는 valueBuffer가 존재하고, Value Witness Table과 Protocol Witness Table에 대한 참조를 담고 있는 프로퍼티(포인터)를 가지고 있습니다.

따라서 drawACopy(val)가 실행이 되면, Swift는 local이라는 변수에 새롭게 생성하여 Stack 메모리에 올라간 Existential Container 객체를 할당합니다.
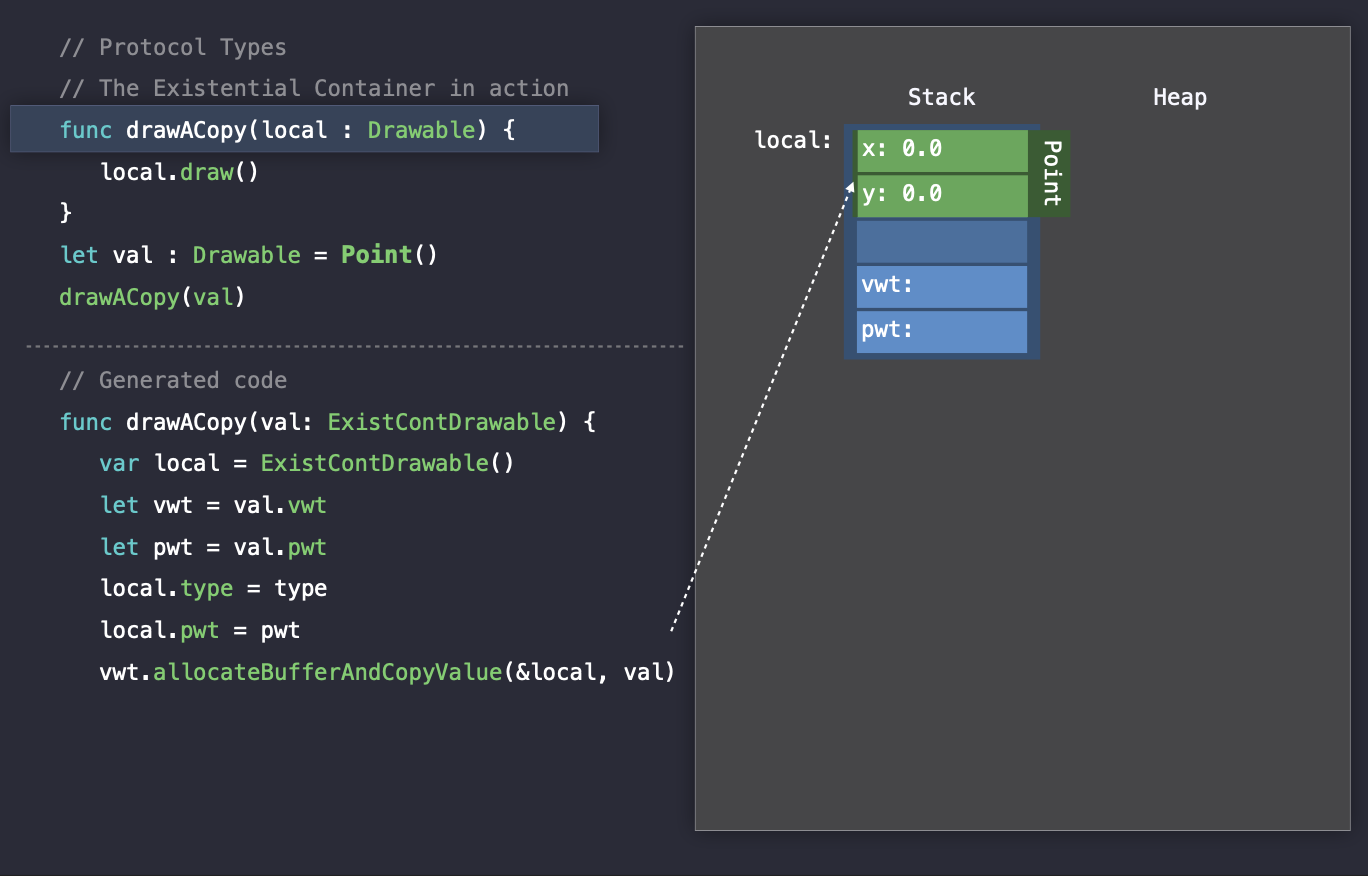
그리고, argumen로 들어온(val) exsitential container의 vwt와 pwt를 읽어옵니다. 그리고 새롭게 만든 existential container를 초기화합니다. 필요한 경우에는 추가적으로 valueBuffer 값을 할당하고, copy() 함수를 호출합니다. 그리고 마지막으로 argument의 값을 local의 valueBuffer에 복사합니다.
그래서 결과적으로 Point와 Line의 경우에는 각각 아래와 같이 그림이 그려집니다.


그러면 실제로 draw() 함수가 호출될 때는 확인해 봅시다.
(앞서 local이라는 변수에 새롭게 만들었던 Existential Container를 argument에 들어오는 Existential Container의 값으로 싹 다 넣어주었으니까, 완성된 Existential Container의 PWT만 확인하면 되겠죠!)

draw() 함수가 호출되는 순간, Swift는 Existential Container(local)의 pwt를 조회하고, pwt 속 draw 메소드의 구현부를 찾아서 실행합니다. 그런데 여기서 또 다른 value witness call인 projectBuffer가 존재합니다. 여기서 projectBuffer는 무엇일까요?
draw 메소드는 input으로 value의 주소값이 들어오길 예상합니다. 근데 value가 inline buffer에 맞는 Point(valueBuffer에 딱 들어맞는)와 같이 주소가 Existential Container의 시작과 같은 타입도 있고, Line과 같이 inline buffer에 맞지 않아서 heap에서 시작하는(valueBuffer에 딱 들어맞지 않아서 heap에 저장되는!) 메모리 주소도 존재합니다. 그래서 projectBuffer는 타입에 따른 차이점을 추상화해 주는 역할을 합니다.
쉽게 말해서, 최종적으로 pwt를 통해서 draw 메소드를 호출하는데, input값으로 해당 객체의 주소 값이 들어와야합니다. 근데, Point의 경우 주소 값이 Existential Container의 시작이고 Line의 경우 주소 값이 Heap에 존재합니다. pointBuffer는 이 차이점을 추상화해주는 역할을 하여, draw에 알맞는 객체의 주소 값을 넣어줄 수 있게 합니다.

이렇게 draw 메소드가 실행되고 나면, local 변수는 스코프에서 벗어나게 됩니다. 이럴 경우, Swift는 vwt의 destruct함수를 호출하여 reference count를 감소시킵니다.
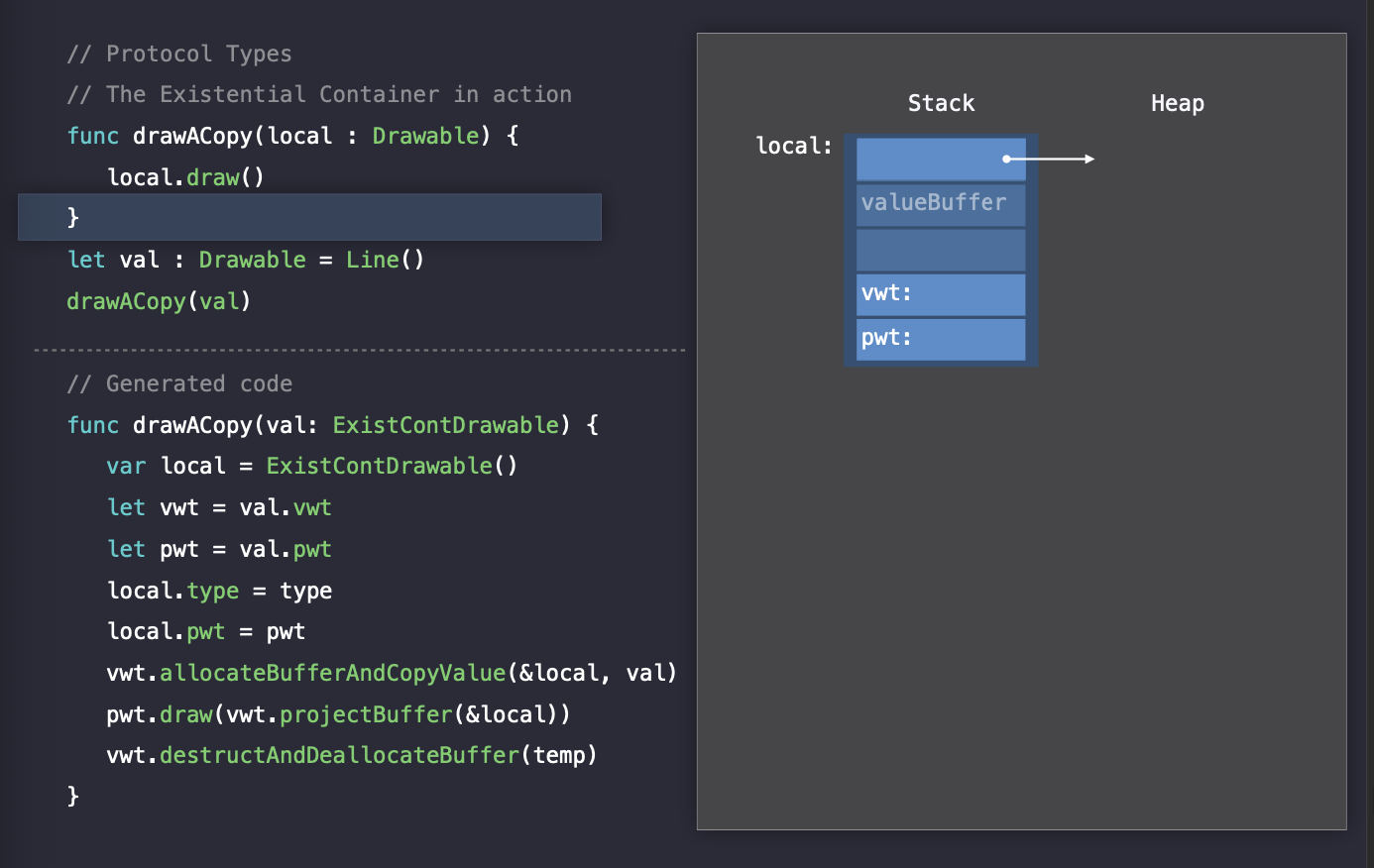
그리고 결과적으로 buffer가 할당되어 있다면 deallocate을 하게 됩니다.
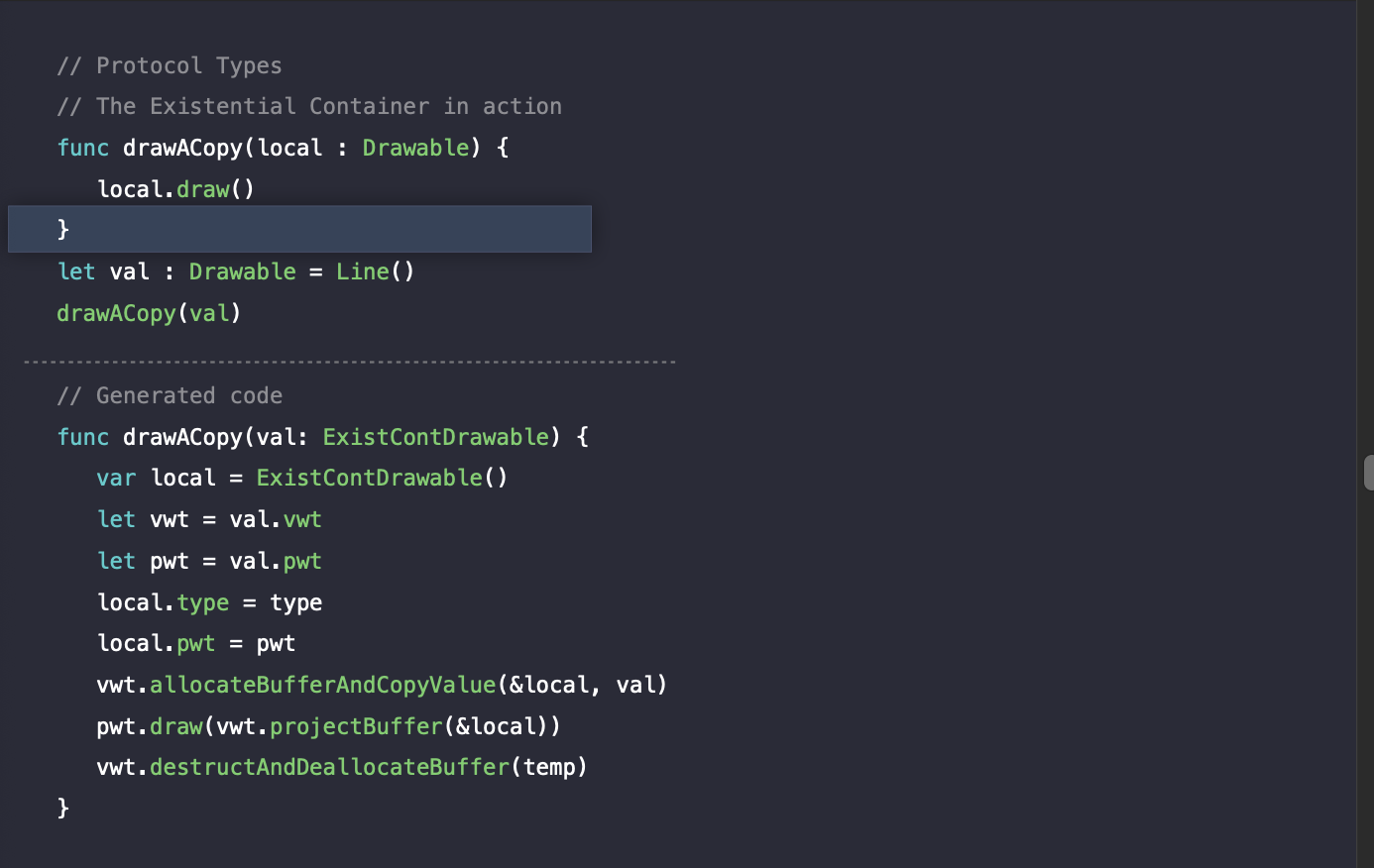
그리고 최종적으로 함수의 실행이 끝나게 되면, 스택에서 로컬 existential container를 삭제하게 됩니다.
이러한 방식을 통해서 struct 타입과 protocol을 활용하여 Dynamic Behavior(Dynamic Polymorphism)을 수행할 수 있었습니다. 즉 Line과 Point를 drawable protocol 타입의 배열에 넣을 수 있는 행동을 할 수 있게 해주고, 알맞은 draw 메소드를 호출할 수 있게 합니다.
Protocol 타입의 저장 프로퍼티와 관련된 예를 하나를 보겠습니다.

위와 같이 Pair 타입은 drawable 타입의 프로퍼티 두 개를 가지고 있습니다. 이럴 경우에는 어떻게 existential container가 만들어질까요?

Swift는 두 개의 existentail container를 생성하고, Pair 구조체로 2개의 container를 감쌉니다. Line은 heap에 프로퍼티를 메모리 할당하고 valueBuffer에는 해당 메모리 포인터를 저장합니다, Point는 inline valueBuffer에 딱 맞기에 container안에 저장이 됩니다.(stack에 존재!)

근데 만약 코드를 위와 같이 바꾸게되면, 할당이 2개가 됩니다. 이럴 경우에는 heap allocation cost가 그전보다 더 발생하겠죠?
그럼 더 극단적인 예를 생각해 봅시다. 아래와 같이 copy라는 상수 값이 추가되었다고 가정해 봅시다.

이럴 경우, 위와 같이 총 4개의 heap allocation이 발생하게 됩니다. 즉, line 타입은 3 words 이상이므로 heap에 값을 할당하기 때문에 이러한 문제가 발생하게 됩니다.
그렇다면 위의 코드 중 Line을 class로 바꿔보면 어떻게 될까요?

이렇게 구현이 됩니다. First 복사한 Second가 존재한다고 하면, 둘 다 같은 Line class 객체를 바라보고 있죠!! 이때 저희가 지불해야 되는 것은 오직 reference count의 1 증가뿐입니다. heap Allocation은 한 개뿐이죠. 그러나, 이럴 경우 first 인스턴스의 값이 변화가 되면 second 인스턴스의 값도 같이 변화하게 됩니다. 그렇다면 이러한 문제없이 value semantics를 사용할 수 있는 방법은 무엇이 있을까요?
위와 같은 문제는 COW(Copy On Write)를 통해서 구현할 수 있습니다.

위와 같이 LineStorage class가 정의했습니다. 그리고 Line이라는 구조체는 LineStorage 타입의 프로퍼티를 가지고 있습니다.
만약 storage에 있는 값을 변경하려고 할 때는 먼저 storage의 reference count를 확인합니다. 따라서 참조 값이 1보다 크다면, LineStorage의 복사본을 생성하고 이를 변경합니다. 즉, 변경되지 않고 단순 Line 인스턴스를 복사한 또 다른 Line 인스턴스는 서로 동일한 storage 프로퍼티를 가지고 있는 것입니다.
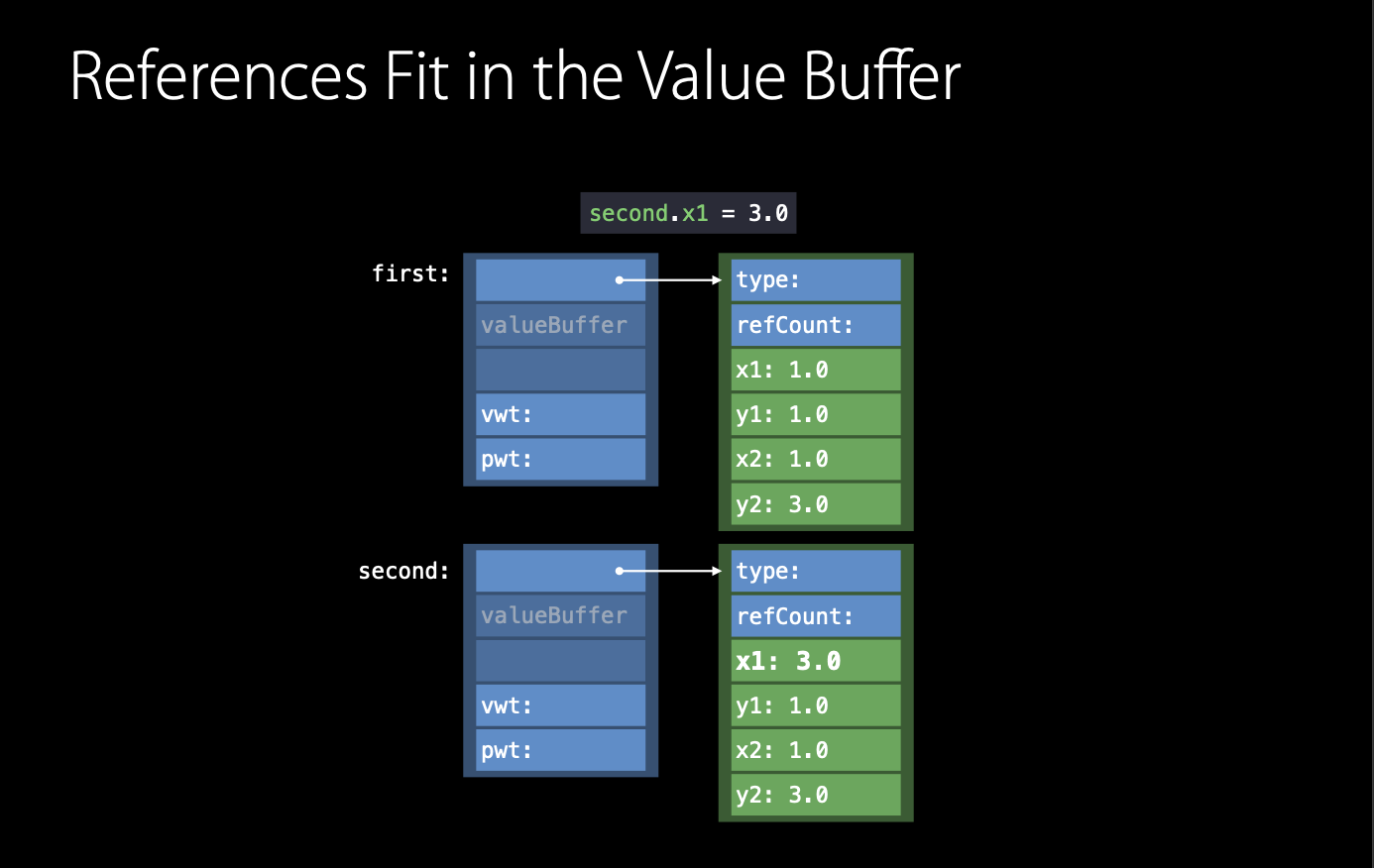
그럼 앞서 말한 문제점을 예를 통해서 해결해 봅시다. 위의 LineStorage를 활용한 아래의 코드를 살펴봅시다.

위와 같이 copy도 서로 똑같은 storage 인스턴스를 가리키고 있습니다. 즉, 현재 copy와 pair는 서로 같은 것을 공유하고 있는 것입니다. 근데 만약 copy가 storage의 프로퍼티를 변경한다면? (ex. second.x1 = 3.0) move() 함수가 호출이 되고, storage의 참조 카운드를 확인합니다. 그래서 위와 같은 경우에 같은 storage를 여러 곳에서 참조하고 있으므로 이때서야 새로운 storage 인스턴스를 생성하는 것입니다. 그래서 결과적으로 아래와 같은 코드가 됩니다.
그러면 이제 위의 내용들이 무엇을 뜻하는 정리해보겠습니다.

만약 프로토콜 타입이 existential container의 inline valueBuffer에 딱 들어맞는 작은 값들을 가지고 있다면 heap allocation은 발생하지 않습니다.
또한 struct이 어떠한 참조도 가지고 있지 않으면, reference counting을 하지 않으므로 매우 빠른 코드가 됩니다.
그러나, 어떠한 경우에는 vwt와 pwt를 통해서 다이나믹한 polymorphism 행동을 가능하게 하는 dynamic dispatch를 할 수 있게 됩니다.(성능이 떨어지겠죠?.. )


만약 프로토콜이 큰 value를 가지고 있을 경우, 해당 값을 초기화하거나, 할당할 때에 heap allocation이 발생합니다. 또한 참조 값을 가지고 있을 경우, reference counting을 하게 됩니다. 그러나, 방금 위의 예에서 했던 것과 같이 indirect storage를 활용할 경우, 값비싼 heap allocation을 피할 수 있습니다. 그러나, reference counting을 더 자주 하게 되겠네요.
'Swift' 카테고리의 다른 글
| [Swift] [weak self]는 언제 사용할까? (0) | 2023.08.11 |
|---|---|
| [Swift] WWDC16 Understanding Swift Performance(3) (0) | 2023.08.03 |
| [Swift] WWDC16 Understanding Swift Performance(1) (0) | 2023.07.31 |
| [Swift] 다형성을 활용하여 Enum 대체하기 (0) | 2023.07.26 |
| [Swift] 다형성과 추상화 (0) | 2023.07.14 |